Definitional reference · Last verified July 2026
Agentic deep research explained from the ground up
You've probably seen AI tools that claim to "do research" for you. You type a question, the AI searches the web, and a few seconds later you get a fluent paragraph with some links at the bottom. It reads well. It sounds confident. And you have no way to know if it actually found the right things, missed important things, or made something up.
Agentic deep research is the approach that fixes this. Instead of a single search-and-summarize pass, an autonomous AI agent plans what to research, searches the web iteratively across multiple rounds, evaluates every source it finds, discards the weak ones with documented reasons, and synthesizes a cited report from only the evidence that survived scrutiny. This page explains the category, why it matters, and how Nodalist's AI Grounding implements it.
The problem with how AI does research today
Imagine you're making an important decision. Maybe you're researching a medical condition, evaluating a business opportunity, writing an academic paper, or deciding whether to invest in something. You need real evidence, not just a smart-sounding answer.
So you ask an AI. And the AI gives you a beautifully written paragraph. It mentions some statistics. It cites a few sources. It sounds like it knows what it's talking about.
But here's what actually happened behind the scenes: the AI ran one or two web searches, grabbed the top results, skimmed them, and wrote a summary. It didn't check whether those sources were authoritative. It didn't look for sources that might contradict the first ones it found. It didn't evaluate whether the evidence was recent enough to be relevant. And it definitely didn't tell you about the sources it didn't find — the gaps in its research that it papered over with confident prose.
This isn't a failure of intelligence. The AI might be extremely capable. The problem is structural: a single search-and-summarize pass is not research. Research requires planning what to look for, iterating when the first results aren't good enough, evaluating the quality of what you find, and being honest about what you didn't find. None of that happens in a single pass.
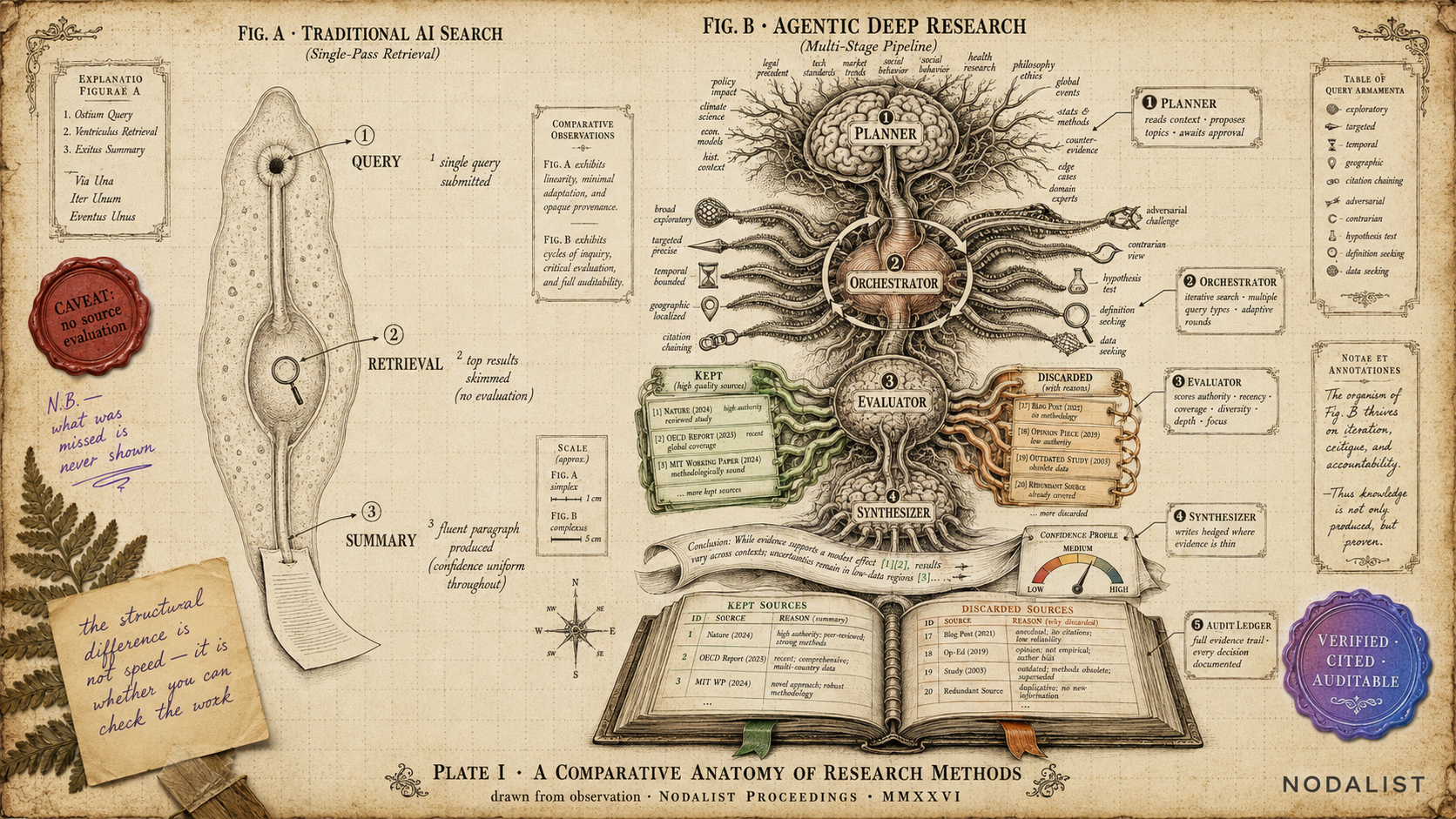
What agentic deep research actually is
Let's break the term down, because both words matter.
“Agentic” means the AI acts autonomously across multiple steps
In most AI interactions, you send a prompt and get a response. One step. With an agentic system, the AI doesn't just answer — it works. It plans what to do, executes the plan step by step, evaluates the results, and decides what to do next based on what it found. The human sets the goal and reviews the work. The agent does the legwork.
Think of it like the difference between asking someone a question and hiring someone to investigate. The question gets you an answer. The investigation gets you evidence.
“Deep research” means going beyond the first page of results
Standard AI search finds things. Deep research investigates. That means multiple rounds of searching, with each round informed by what the previous round found. It means evaluating sources for quality, not just relevance. It means pursuing leads that didn't show up in the obvious query. And it means being honest about what the evidence does and doesn't support.
A researcher doesn't open Google, read three links, and write their paper. They read broadly, follow citations, check publication dates, compare conflicting findings, and make judgement calls about what to trust. Deep research means the AI does this too.
Put together: agentic deep research is an AI system that investigates a question the way a diligent researcher would — planning what to look for, searching iteratively, evaluating what it finds, and producing work you can verify.
What it is — and what it isn't
The term gets mixed up with several adjacent concepts. Here's where the boundaries are.
✓ It is: autonomous, multi-step investigation with source evaluation
The agent plans its approach, runs multiple rounds of searches, scores every source it finds, keeps the good ones, documents why it discarded the rest, and writes a synthesis grounded in the surviving evidence. The output is auditable: you can trace every claim back to its source and see what was considered but excluded.
✗ It isn't: standard AI search (one query, one answer)
When an AI runs one web search and summarizes the top results, that's retrieval with generation — not research. No planning, no iteration, no evaluation, no discard decisions. The output may look like research because it mentions sources, but the process behind it is fundamentally different.
✗ It isn't: RAG (Retrieval-Augmented Generation)
RAG retrieves chunks from a pre-indexed corpus and feeds them to a language model as context. It's a retrieval technique, not a research methodology. RAG answers "what does our database say about X?" Agentic deep research answers "what does the world know about X, how trustworthy is it, and what's missing?" They operate at different levels.
✗ It isn't: a manual AI research assistant you micromanage
Some tools let you tell an AI exactly what to search for, review each result manually, and build your own bibliography. That's human-driven research with an AI helper. Agentic deep research inverts the relationship: you set the goal and approve the plan; the agent does the searching, evaluating, and organizing autonomously. You review the output, not every intermediate step.
✗ It isn't: a replacement for human expertise
Agentic deep research handles the labor-intensive part of research — finding, evaluating, and organizing public web sources. It cannot run original experiments, conduct interviews, access paywalled archives, or apply the domain intuition that comes from years of experience. It's a research multiplier, not a research replacement.
How agentic deep research works
Every serious implementation follows a version of this five-stage pattern. The stages can be named differently, but the jobs are always the same.

1 Planning: deciding what to look for
The first thing a good researcher does is not open a search engine. They think about the question. What angles matter? What would strong evidence look like? What specific topics need separate investigation?
An agentic deep research system does the same thing. Before any web search happens, the agent analyzes your question, breaks it into distinct research topics, and assigns each topic a strategic purpose — why it matters to the overall question. This plan is the research strategy. It determines what gets investigated and what doesn't.
In good implementations, you see and edit this plan before the agent starts working. This is where you stay in control without micromanaging — you shape the direction, the agent does the execution.
2 Iterative search: going beyond the obvious
This is where agentic research diverges most sharply from standard AI search. Instead of running one query and taking the top results, the agent searches iteratively. Each round generates different types of queries:
- Exploratory queries cast a wide net to map the landscape
- Targeted queries drill into specific claims or data points
- Adversarial queries deliberately search for contradicting evidence
Each round is informed by the previous one. If the first round finds a strong claim, the next round might search for evidence that challenges it. If the first round finds nothing useful, the agent reformulates its approach. This iterative process is what makes the research deep — the agent doesn't settle for the first thing it finds.
3 Source evaluation: separating signal from noise
Finding information is easy. Knowing which information to trust is hard. This is the stage most AI tools skip entirely.
In agentic deep research, every source the agent finds is evaluated against the topic's specific intent. The evaluation typically measures multiple dimensions:
- Authority: Is this source credible for this specific claim?
- Recency: Is the information current enough to be useful?
- Coverage: Does the source address the question deeply, or just mention it?
- Diversity: Are we getting perspectives from different viewpoints?
- Depth: Is the evidence substantive, or surface-level?
- Focus alignment: Does this actually answer what we were looking for?
Sources that don't meet the bar are discarded — but the discard is documented, not silent. A good system tells you what it threw away and why, because the quality of the research depends on the quality of those discard decisions just as much as on the inclusions.
4 Synthesis: writing what the evidence actually supports
This is where the report gets written. But unlike a standard AI summary, the synthesis is constrained by the evaluation. The agent writes confidently where the evidence is strong and hedges explicitly where the evidence is thin or contested.
This might sound like a small detail, but it's the difference between useful research and misleading research. Most AI tools produce text that sounds equally confident about everything — a well-supported statistic and a weakly sourced opinion get the same smooth, assured prose. Agentic deep research preserves the uncertainty. When you read the output, you can tell which findings are rock-solid and which ones need more investigation.
5 Audit trail: showing the work, not just the answer
The final output of agentic deep research isn't just a report — it's a report plus the complete evidence trail. You can see:
- Which sources were kept and why
- Which sources were discarded and why
- How confident the agent is in each section
- Where the evidence is strong and where gaps remain
This audit trail is what makes the output verifiable. You don't have to trust the AI's answer — you can check its homework. Research you can't audit isn't research. It's a confident guess.
Why agentic deep research matters now
Three things happened at the same time that made this category possible — and necessary.
AI got good enough to evaluate, not just generate
Earlier language models could generate text and search the web, but they couldn't reliably judge whether a source was authoritative, whether evidence was contradictory, or whether a topic was sufficiently covered. The 2024–2026 generation of models crossed a threshold: they can now make source-quality judgements that are useful (not perfect, but useful) for research tasks. Without this capability, the evaluation and discard stages of agentic deep research wouldn't work.
AI confidence became a recognized problem
People learned — sometimes the hard way — that AI answers sound confident regardless of whether they're correct. The "hallucination" problem made headlines. Users started asking: "how do I know this is right?" Agentic deep research is a structural answer to that question. Instead of asking users to trust the output, it shows the work: here are the sources, here's what was kept, here's what was thrown away, here's how confident we are in each section.
The stakes got higher
As AI became more capable, people started using it for more consequential decisions. Market research. Investment analysis. Medical information. Academic work. Policy research. These are domains where a wrong answer costs real money, real credibility, or real outcomes. Single-pass AI search was fine for casual questions. For high-stakes work, people needed something they could verify and defend.
Research that doesn't vanish
There's a quieter problem with ordinary deep research, and it has nothing to do with source quality. The agent works for ten minutes, produces a long, well-cited answer — and then the answer sits in a chat thread, above whatever you type next. Scroll on, and it's buried. Start a new conversation, and it's gone. You paid for that research — in time or in money — and it evaporated the moment the conversation moved on.
Research that expensive shouldn't be disposable. If you want to save deep research results and actually build on previous AI research, the output has to be a persistent artifact — something with an address, not a message in a scroll. In Nodalist, every AI Grounding session lands on your canvas as exactly that. It does not vanish after one answer. It stays as a living record you can reuse, branch from, and build on.
That changes what research is for. You can reuse AI deep research as context for the next question instead of re-running it. You can branch three lines of thinking off one report. You can come back in a month and the evidence trail is still there, still connected to the reasoning it supported. The research stops being an endpoint and becomes a foundation.
Who uses agentic deep research?
The common thread isn't an industry — it's a situation. You use agentic deep research when the cost of being wrong is higher than the cost of checking.
Founders and business leaders
Market research, competitive landscape analysis, regulatory environment scanning. Decisions that commit budget, headcount, or strategy direction.
Researchers and academics
Literature surveys, evidence mapping, cross-disciplinary synthesis. The part of research that involves finding and organizing what's already known before adding original work.
Consultants and analysts
Client deliverables that need cited evidence. Industry reports, due diligence memos, strategic assessments. Work that gets challenged and needs to hold up.
Students
Thesis research, paper preparation, topic exploration. Learning how to evaluate sources is part of the education — an auditable research output teaches the process, not just the answer.
Investors
Due diligence on companies, sectors, and technologies. Understanding what the public record says before committing capital.
Anyone with a hard question
Should I move to this city? Is this medical treatment evidence-based? What do experts actually say about this policy? When the answer matters enough to check, agentic deep research is the right tool.
Evaluating a tool? Use the buyer's checklist
This page defines the paradigm. If you’re comparing products and want the practical buyer’s-guide — the five things that separate real agentic deep research from search-and-summarize with a better label, the decision rule for when you actually need one, and real scenarios — that lives on its own page.
→ How to choose an AI research tool walks through the full evaluation checklist and the five levels of research quality.
How Nodalist implements agentic deep research
Nodalist's implementation is called AI Grounding. It runs a four-stage pipeline — Planner, Orchestrator, Evaluator, Synthesizer — inside a visual reasoning workspace. Here's how the five criteria above map to the actual product.
Plan review before any cost
The Planner reads your canvas context — not just the node you clicked, but the entire branch of thinking you've built: ancestor nodes, connected files, earlier decisions. It proposes a list of research topics, each with a label, description, and strategic why. You see the plan, edit it, add or remove topics. No credits are spent until you approve.
Iterative web search with multiple query types
The Orchestrator runs multiple search iterations per topic, generating exploratory, targeted, and adversarial queries. High-priority topics get more depth. The Orchestrator decides when a topic is well-covered and stops, so the research budget is spent where it matters most.
Six-axis source evaluation + References Audit Ledger
An independent Evaluator scores each topic across coverage, authority, recency, diversity, depth, and focus alignment. The References Audit Ledger shows every source considered — kept ones with their inclusion reasoning, discarded ones with their exclusion reasoning. The Ledger is viewable on the canvas node and exported in the PDF.
Evaluation-constrained synthesis
The Synthesizer writes the final report honoring the Evaluator's scores. Strong evidence gets confident treatment. Thin evidence gets an explicit hedge. The Synthesizer cannot override the Evaluator's flags — the architecture enforces intellectual honesty at the structural level.
Canvas-native output that connects to your thinking
The report lands on your canvas as a persistent, branchable node. Connect it to other nodes. Feed it into AI Storming so six AI models can debate the evidence. Use it as ancestor context for your next AI generation. Export the full audit as a PDF with a Field Notebook cover page. The research is part of your reasoning workspace — not a standalone document you copy-paste from and lose track of.

What it costs
Agentic deep research costs more than a single AI query because the agent runs multiple searches, evaluations, and a synthesis step. But it costs dramatically less than the human time it replaces. A research session that would take 4–8 hours of manual browser-tab work typically completes in under 10 minutes.
In Nodalist, AI Grounding is included in every plan. You see the credit estimate before approving the research plan, so there are never cost surprises.
Free
$0 / month · 250 credits
1 AI Grounding session per day. Full canvas, AI modes, and AI Storming included.
Paid plans
Starter $5.99 · Pro $14.99 · Enterprise $99
No daily limit on AI Grounding. File uploads, OCR, folder bundles, full PDF export.
The bigger picture: research inside a reasoning workspace
Most agentic deep research tools exist in isolation. You ask a question, you get a report, the report sits in a document somewhere. The research is an endpoint.
In Nodalist, AI Grounding is one capability inside a larger visual reasoning workspace. The same canvas where you run deep research also lets you:
- → Break down complex problems into structured sub-questions using AI-powered Breakdown mode
- → Make decisions by mapping options, criteria, and tradeoffs using Decision mode
- → Generate creative possibilities using Generative mode for lateral thinking
- → Run multi-AI debates with AI Storming — six AI models debating one question
- → Attach files — PDFs, documents, spreadsheets — as context for any AI operation
All of these capabilities live on the same canvas, connected by edges, building on each other's context. An AI Grounding node connects to the question that spawned it. That question connects to earlier work. The next AI operation reads the grounded evidence as context. The thinking is cumulative, not episodic.
Research is not the end of thinking. It's what makes the rest of the thinking trustworthy. That's why it belongs on the canvas, not in a separate tool.
Frequently asked questions
What is agentic deep research?
Agentic deep research is an AI research paradigm where an autonomous agent plans its own research strategy, searches the web iteratively across multiple rounds, evaluates every source it finds, and synthesizes the results into a structured, cited output. Unlike standard AI search (one query, one answer), the agent decides what to look for, how deep to go, when evidence is sufficient, and what to discard. The word 'agentic' means the AI acts autonomously across multiple steps rather than responding to a single prompt.
How is agentic deep research different from asking ChatGPT or Google a question?
When you ask a chatbot a question, it generates an answer from its training data — sometimes with a single web search attached. Agentic deep research is fundamentally different: the agent plans multiple research topics, runs dozens of searches across iterations, evaluates every source against your specific question, discards weak evidence with documented reasons, and synthesizes only from verified sources. The output is a cited report you can audit, not a fluent paragraph you have to trust.
What does 'agentic' mean in this context?
In AI, 'agentic' means the system acts autonomously across multiple steps to achieve a goal — planning its own actions, executing them, evaluating the results, and deciding what to do next. An agentic research system doesn't just answer your question; it figures out what questions to ask the web, searches for answers, judges whether the answers are good enough, and keeps going until the research goal is met. The human sets the goal and reviews the plan; the agent does the legwork.
Why does the planning step matter?
Without a planning step, the AI searches for whatever sounds related to your question. With planning, the agent breaks your question into specific research topics, each with a strategic reason it matters. This prevents two common failure modes: researching too narrowly (missing important angles) and researching too broadly (drowning in tangentially related results). The plan is also the point where you stay in control — you can edit, add, or remove topics before the agent spends any time or credits searching.
What makes the evaluation step important?
Most AI systems that search the web treat every result as equally valid. Agentic deep research evaluates every source against the topic's intent — measuring authority, recency, coverage, diversity, depth, and focus alignment. Sources that don't meet the bar are discarded with a documented reason. This is what separates research from retrieval: research involves judgement about what counts as evidence, not just finding things that mention the right keywords.
Can agentic deep research replace a human researcher?
No. Agentic deep research handles the time-consuming part of research — finding, reading, evaluating, and organizing sources across the open web. It cannot interview people, access paywalled databases, run original experiments, or apply the kind of domain expertise that comes from years in a field. Think of it as a research assistant that gets you to the right questions faster, shows its work along the way, and saves you the hours you would have spent opening browser tabs. The judgement about what the evidence means is still yours.
How is agentic deep research different from RAG (Retrieval-Augmented Generation)?
RAG retrieves chunks of text from a pre-indexed corpus and feeds them to a language model as context. It is a retrieval mechanism, not a research methodology. Agentic deep research uses search and retrieval as one tool among several — it also plans, evaluates, iterates, discards, and synthesizes. RAG answers the question 'what does our corpus say about X?' Agentic deep research answers the question 'what does the world know about X, how reliable is it, and what's missing?' They operate at different levels of the stack.
What kind of questions is agentic deep research best for?
Questions where the answer requires evidence from multiple sources, where the quality of the sources matters, and where a wrong answer would be costly. Examples: market research for a business decision, academic literature review, competitive landscape analysis, policy research, investment due diligence, medical condition research (non-diagnostic), technical architecture decisions. Not ideal for simple factual lookups ('what is the capital of France?') or subjective preference questions ('what is the best restaurant in Paris?').
How does Nodalist implement agentic deep research?
Nodalist's implementation is called AI Grounding. It runs a four-stage pipeline — Planner, Orchestrator, Evaluator, Synthesizer — inside a visual reasoning workspace. The Planner reads your canvas context (not just the question, but the entire branch of thinking you have built so far) and proposes research topics. You edit and approve the plan. The Orchestrator searches iteratively. The Evaluator scores every source. The Synthesizer writes a cited report that lands on your canvas as a persistent, branchable node — paired with a References Audit Ledger showing every source considered, kept, and discarded. The research becomes part of your reasoning, not an isolated answer.
Is agentic deep research expensive?
It costs more than a single AI query because the agent runs multiple searches, evaluations, and a synthesis step. But it costs dramatically less than the human time it replaces. A research session that would take a person 4–8 hours of browser-tab work typically completes in under 10 minutes. In Nodalist, AI Grounding is included in the Free tier (one session per day) and in all paid plans (no daily limit, from $5.99/month). You see the credit estimate before approving the plan, so there are no cost surprises.
Further reading
- What is AI Grounding? — the full reference for Nodalist's implementation: four-stage pipeline, References Audit Ledger, Field Notebook PDF, pricing.
- AI Research Tool: What to Look For — practical buyer's guide: the five levels of AI research, real scenarios, what to look for, and how Nodalist's works.
- AI Storming — the upward counterweight: six AI models debating one question until they reach consensus. Storm to explore, ground to verify.
- Multi-LLM Debate — the category definition and peer-reviewed research behind structured AI debate.
- All Nodalist features — the complete visual reasoning workspace: AI modes, file intelligence, folder bundles, journey export.
- Pricing — plans, credits, and what's included at each tier.
Try agentic deep research on your next hard question
AI Grounding is the agentic deep research capability inside Nodalist — the visual reasoning workspace. Plan your research, search iteratively, evaluate every source, and get a cited report you can audit and build from. Free to start.
Try AI Grounding free